
Your engineers are shipping AI-generated code every day. Your QA process probably hasn’t changed since 2020. That gap is expensive. Bugs slip to production. Release cycles stretch. Your best engineers spend Friday afternoons fixing broken test scripts. Autonomous testing agents are how fast-moving teams are closing that gap.
This guide covers what they are, how they work in software testing, the tools worth evaluating, and the one question most companies skip: how do you know the agent itself is actually reliable?
What Are Autonomous Testing Agents?
An autonomous testing agent is an AI system that plans, creates, executes, and maintains software tests on its own, without pre-written scripts or manual configuration for every test case.
Give it a goal: “verify a user can complete checkout.” The agent decides the path, finds the elements, and runs the assertions. You write the outcome you want, not the steps to get there.
The technical architecture behind autonomous testing agents combines 3 layers:
- The reasoning layer (LLM): A large language model generates test scenarios from requirements, interprets failure messages, and decides what to test next based on application context.
- The context layer (RAG): Retrieval-augmented generation connects the LLM to your actual application. Your PRDs, API specs, Jira tickets, and existing test coverage feed into this layer. Without it, the agent generates generic tests.
- The execution layer (AI agents): The agent navigates a browser, fills forms, calls APIs, compares actual results to expected ones, logs bugs, and updates tickets. No human initiates any of those steps.
All 3 layers together are what separates a true autonomous testing agent from a test script generator that still needs a human to run it.
What Is Traditional Test Automation?
Traditional test automation uses scripted frameworks to execute pre-defined test cases. Engineers write code that drives a browser or API client through specific steps, checks expected outcomes, and reports pass/fail.
It’s been the go-to approach for 20+ years, and it still works in the right scenarios. But it’s no longer the best fit for engineers building and shipping at AI speed.
Move from traditional automation to autonomous testing in 48 hours
Common Tools and Approaches of Traditional Automation
- Record-and-playback tools like Selenium IDE and Katalon Recorder lower the barrier to entry by capturing user interactions and replaying them as scripts. Any UI change, a renamed button, a shifted layout, breaks the recording. These tools produce brittle tests by design.
- Code-based frameworks like Selenium WebDriver, Cypress, and Playwright give engineers full programmatic control. Tests integrate cleanly into CI/CD pipelines and are maintainable when written well. But a moderately complex checkout flow can take a senior QA engineer 2 to 4 hours to script and stabilize, and that’s before anyone changes anything.
- BDD frameworks like Cucumber and Behave wrap scripts in human-readable Gherkin syntax. This improves collaboration between QA and product teams. The scripts underneath are still hand-written and hand-maintained.
All 3 approaches share the same structural constraint.
The Core Limitation of Traditional Automation
The ongoing maintenance cost is what breaks teams. A survey found 59% of QA teams cite test maintenance as their biggest pain point. Every UI refactor, every feature flag, and every A/B test variant can potentially break dozens of existing scripts.
Traditional scripts encode how to interact with a UI, making them tightly coupled to implementation details. Change the implementation and the test breaks, even if the behavior is exactly right.
Autonomous testing agents shift that burden. Instead of hand-fixing broken selectors, you calibrate the agent’s goals and review the output.
How Autonomous Testing Agents Work
The workflow looks simple. Underneath, it’s doing something significantly more complex than any test framework.
- Start with a goal, skip the script
Tell the agent what to verify in plain language: “Confirm a new user can sign up and receive a confirmation email.” The agent builds an execution plan from your app’s actual structure. No selectors, no code, no framework setup.
- The agent reads your application
Before touching a single UI element, it ingests your context: PRDs, Figma files, user stories, screenshots, API docs. It builds a working model of how your application is supposed to behave.
- The agent explores and executes
It navigates pages, fills forms, clicks through flows, and tries edge cases a human tester would consider but often skip. If an unexpected modal appears mid-run, it handles it rather than failing.
- It adapts when things change
When a UI element changes, traditional automation breaks. An autonomous agent finds the correct element by semantic context, updates its approach, and continues. This self-healing behavior is the biggest practical advantage for teams with high UI churn.
- Human validation before results ship
The best implementations don’t send raw AI output straight to your engineers. A human review layer catches false positives, validates edge cases that the AI misreads, and ensures that bug reports are actionable.
- Actionable reporting
Output is a structured bug report: what failed, the expected behavior, step-by-step reproduction steps, screenshots, and root cause analysis. Product managers can read it without translation. Engineers can act on it without guessing.
BotGauge brings AI agents to every phase of the testing lifecycle, with every outcome validated by domain-specific FDE pods through a built-in human validation layer.
Explore how AI agents + FDE pods make test automation autonomous
Best Practices for Testing Autonomous AI Agents
Testing the reliability of autonomous AI agents is where most teams get stuck. Running an autonomous agent without validating its own output is like hiring a QA engineer and never reviewing their bug reports.
The agent might miss real bugs, file false positives, or test paths that don’t reflect actual user behavior. These best practices separate teams that get real value from autonomous testing from those that tried it and quietly went back to Selenium.
1. Define acceptance criteria before the agent runs
Autonomous agents generate tests, but tests need something to measure against: a clear definition of what correct behavior looks like. Without documented acceptance criteria, agents reflect current behavior rather than intended behavior.
Your agent can pass 500 tests, and each one validates a broken flow because no one specified the correct flow. Write acceptance criteria before pointing the agent at any new feature.
2. Validate agent output with a human review layer
AI-generated tests produce false positives. The agent thinks something failed when it didn’t, or passes a test that should have caught a real bug. A human review step before results hit your engineering team’s inbox keeps trust in the system high.
Sampling works fine. Review new feature tests closely; spot-check stable flows monthly. Build clear escalation paths for anything that looks wrong.
BotGauge redefines software testing with Autonomous QA as a Solution (AQaaS). AI agents drive every stage of the testing lifecycle, and domain-specific FDE pods ensure every output is accurate, reliable, and production-ready through built-in human validation.
3. Run reliability checks on a known-stable baseline
Pick a part of your application that hasn’t changed in 60 days. Point your autonomous agent at it. If the agent reports failures, you’ve found an agent reliability problem. If it reports clean, you have a baseline for comparison.
Run this check monthly. Autonomous agents can drift as their underlying models update or as your application’s DOM grows more complex.
4. Measure coverage against your actual user journeys
Most autonomous testing tools report coverage metrics. But coverage metrics only tell you what was tested, not whether the agent is testing what matters to real users.
Map your top 10 user journeys by traffic or business priority. Check whether your autonomous agent is covering them. Gaps between what the agent tested and what users actually do are where bugs hide.
5. Build a feedback loop between production incidents and test coverage
Every production bug that autonomous testing missed is data. When a bug reaches production, ask: was this path covered by the agent? If no, add it. If yes, investigate why the agent didn’t catch it.
This feedback loop, done consistently, makes autonomous testing more reliable over time.
6. Keep human review on high-risk flows
Authentication, payment processing, data deletion, permission changes: these flows have real consequences if a bug ships. Keep a human review on AI-generated test results for any flow where a false negative creates a real business problem.
Autonomous testing agents in software testing are built for breadth. Human judgment is still where depth matters most.
Autonomous Testing Agents Vs Traditional Test Automation
Both approaches have real strengths. The right choice depends on what you’re testing, how fast things change, and who owns the maintenance.
| Traditional test automation | Autonomous testing agents | |
|---|---|---|
| Who writes tests? | Engineers write every script manually | AI generates from requirements or exploration |
| Setup time per flow | Days to weeks | Hours, sometimes minutes |
| Who owns test maintenance? | Manual: engineers fix broken selectors | Self-healing: agent adapts automatically |
| Coverage discovery | Engineers decide what gets tested | Agent explores paths that weren’t specified |
| Bug detection scope | Only catches what was scripted | Can surface bugs in unexplored paths |
| Technical skill required | Senior QA / SDET engineering skills | Zero to minimal: accessible to non-engineers |
| CI/CD integration | Native: scripts run as code | Native, available in most modern platforms |
| Reliability | High: deterministic scripts | High with human validation; variable without |
| False positive risk | Low | Moderate (requires tuning and review) |
| Cost model | High upfront engineering cost + ongoing maintenance | Lower maintenance cost, platform fees |
| Auditability | High: version-controlled code | Varies; best platforms export test artifacts |
| Time to 80% coverage | 4 to 6 months | 2 to 4 weeks with BotGauge |
| Best for | Stable, compliance-sensitive critical paths | Fast-growing engineering teams, SMB to medium businesses, dynamic UIs, broad coverage |
Test scripts are heavy to maintain. They break the moment your UI changes, and someone has to babysit them forever. BotGauge skips that. It uses AI agents that actually understand your app. They write tests, run them, and adapt when your product changes shape. A human QA expert checks the results at every step. So you get speed without losing the human eye on quality.
BotGauge: Autonomous Testing Agent Built for the AI Era
BotGauge owns the entire testing lifecycle, not just the software. Most autonomous testing tools hand you AI and walk away. BotGauge sticks around: it runs the tests, owns the outcomes, and hands your team results they can actually act on.
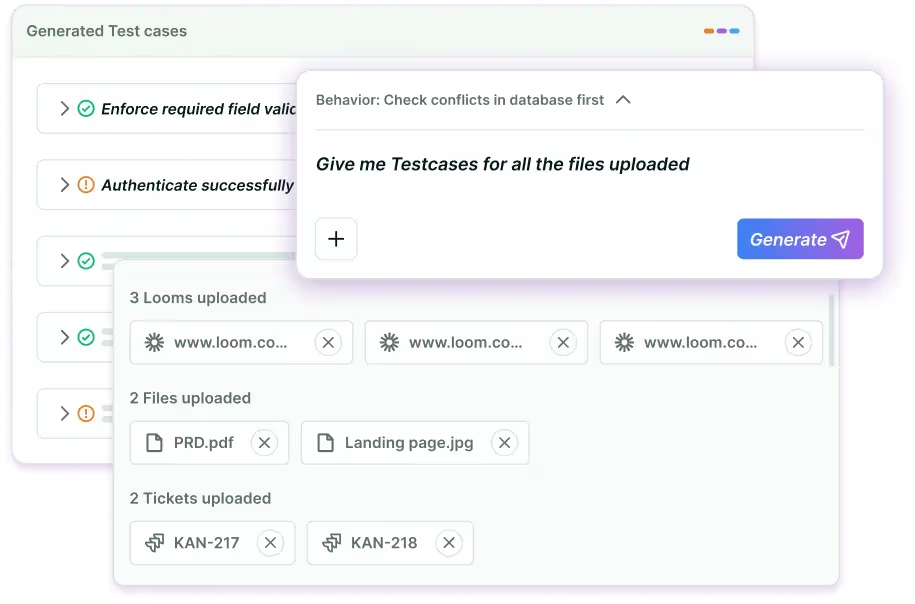
The difference is the model. BotGauge operates as a fully managed autonomous testing partner, combining AI agents with a dedicated domain FDE pod that validates every test before it runs. BotGauge owns the test scripts, maintenance, coverage, and the testing outcomes. Your engineers write code and ship features.
Here’s what AQaaS looks like in practice:
- Share your PRDs, Figma files, or user stories. BotGauge’s AI reads your application and maps every functional, UI, and API workflow.
- The domain FDE pod reviews what the AI generated, catches false positives, and validates coverage before anything runs.
- Tests execute autonomously on every commit. When code changes, tests self-heal. When something breaks, you get an actionable bug report with root cause analysis.
Your engineers ship. BotGauge handles your web app testing end-to-end, from functional UI validation and API testing to chatbot testing.
| 0% flake rate | 6 hrs saved per engineer per week | 10x ROI with autonomous QA | 14 daysto 80% coverage |
Why AI + human experts outperform AI-only tools
AI testing tools generate tests, and no one verifies. Traditional frameworks require your engineers to write everything. BotGauge sits between them: AI does generation at scale, domain QA experts validate before anything ships.
That’s how they achieve a 0% flake rate, even as both pure AI tools and traditional frameworks struggle with false positives and stale scripts.
Enterprise-ready from day one
- SOC 2 Type II certified
- Full data isolation: your application data never trains external AI models
- Your FDE pod signs NDAs and stays embedded in your sprint cycle
- Compliance-sensitive teams in financial services and healthcare can use BotGauge without compromising audit requirements
Integrations your team already uses
Jira, GitHub, GitLab, Linear, Slack, ClickUp, Postman, TestRail, and Xray. BotGauge plugs into your existing CI/CD pipeline. Tests run automatically on every build, with no engineering setup required.
BotGauge x Ripple – The Autonomous Testing Journey
Ripple shipped weekly, and their QA couldn’t keep up. Every release meant 2 to 3 weeks of manual regression testing, spreadsheets, and engineers waiting around for QA to catch up. BotGauge fixed that. Their AI agents took over automated regression testing entirely, automating 80% of it in under a week, and cut execution time by 90%.

Ripple’s engineers haven’t touched test maintenance since onboarding. They build, BotGauge tests, and weekly releases just happen now. Same-day coverage instead of a 3-week wait changes how a team thinks about shipping.
Conclusion
Most QA processes were built for teams shipping every few weeks. Your team probably ships every few days now, sometimes every few hours. Hand-maintained test scripts break faster than anyone can fix them. Coverage falls behind. Release confidence goes with it.
Autonomous testing agents fix the mismatch. They generate tests from your actual requirements, adapt as UIs change, and run on every commit without anyone having to schedule them.
One thing tool comparisons usually skip: autonomy without validation is just faster noise. 400 unreviewed tests calling itself coverage is worse than 50 someone actually thought about. The teams getting real value treat agent output as a starting point, not a finish line.
That’s the gap BotGauge closes. AI generates at scale. A dedicated domain FDE pod validates before anything ships. You get breadth from the agent, accuracy from the human layer.
Frequently asked questions
Can autonomous testing agents replace QA engineers?
Are autonomous testing agents reliable enough for CI/CD pipelines?
Can autonomous testing agents replace manual QA engineers?
What is the cost difference between traditional automation and autonomous agents?
How do you test the reliability of autonomous AI agents?
