
Testing hasn’t kept pace with how fast software ships now.
Script-based automation helped for a while. But teams started spending more time fixing broken tests than writing new ones. Coverage stalled. Bugs still slipped through.
The word “agentic” comes from agency: the capacity to act independently, make decisions, and pursue goals. In software testing, that means systems that don’t just run what you pre-define. They reason about what needs testing, why, and how, then do it. In this blog, we will discuss in detail how Agentic AI testing is shaping the future of software testing.
What Is Agentic AI Testing?
Agentic AI testing is a paradigm shift in software quality engineering, in which autonomous AI agents, powered by large language models (LLMs) and advanced decision-making algorithms, independently plan, generate, execute, adapt, and analyze software tests with minimal human intervention.
Why Agentic AI Testing?
Since 2024, more than 72.3% of QA teams have begun exploring or implementing AI-driven testing workflows, marking a sharp rise from the limited adoption seen just a few years earlier.
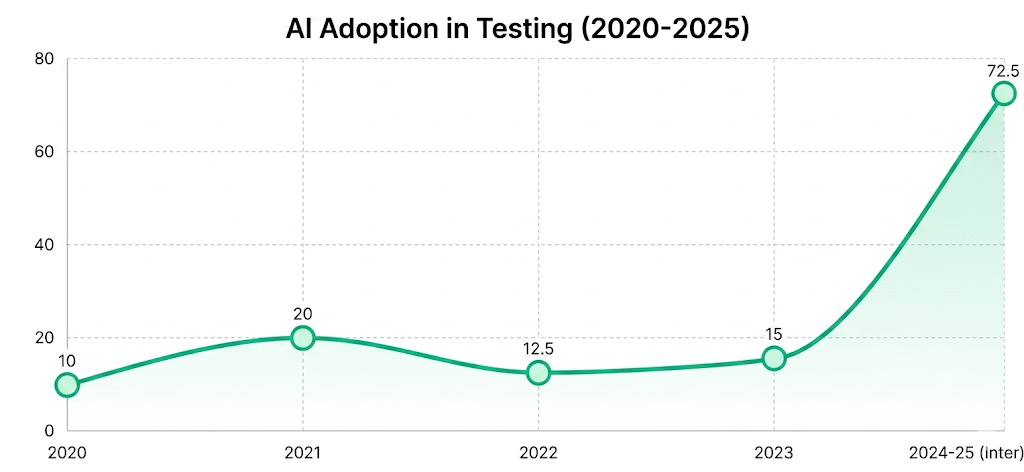
Unlike traditional test automation that follows predefined scripts, or first-generation AI tools that assist with individual tasks like locator healing, agentic AI in testing operates end-to-end across the entire software testing lifecycle.
An agentic testing system can receive a high-level goal, “validate the checkout flow”, and decompose it into sub-tasks, select the right tools, execute tests across environments, self-correct on failure, and produce contextual reports, all without a human writing a single test script.
See what agentic testing actually looks like on your application
How Agentic AI Testing Differs from Traditional Automation
Most existing articles on this topic stop at surface-level comparisons. Here is a comprehensive breakdown that covers what other guides miss:
The Three Eras of Software Testing
Era 1: Manual Testing Testers write test cases by hand, execute them manually, and document results. Slow, human-resource-intensive, and impossible to scale with modern development velocity.
Era 2: Script-Based Automation Tools such as Selenium, Cypress, Playwright, and Appium automate repetitive tasks with scripts. Faster than manual, but brittle, a UI change breaks the test. Teams spend 60% to 80% of their QA effort maintaining test automation, which forces them to fix existing tests rather than build new ones.
Era 3: Agentic AI Software Testing AI agents that plan, execute, self-heal, and learn. No fragile selectors. No manual script updates. An intent-driven model where the agent understands what the user wants to accomplish, not how the DOM is structured.
Side-by-Side Comparison
| Dimension | Traditional Automation | Generative AI Assisted | Agentic AI Testing |
| Test Creation | Manual scripting | AI-suggested scripts | Autonomous generation from requirements |
| Maintenance | Manual after each change | Semi-automated healing | Fully self-healing |
| Execution Control | Predefined paths | Predefined with suggestions | Dynamic, goal-oriented paths |
| Decision Making | None | Limited | Full autonomous reasoning |
| Coverage | Pre-scoped | Pre-scoped with AI hints | Exploratory and risk-adaptive |
| CI/CD Integration | Requires manual setup | Semi-automated | Native, trigger-aware |
| Learning | None | Prompt-level | Cross-run, session, and long-term |
| Multi-agent Support | No | No | Yes – specialized agents collaborate |
| Human Intervention | Constant | Frequent | Minimal (review, not manage) |
If your team is still babysitting test scripts, there's a faster way
The Key Distinction: Generative AI vs Agentic AI in Testing
Generative AI and Agentic AI are not the same thing.
Generative AI responds to a single prompt -> “write test cases for this login form” -> produces output. It doesn’t take initiative, doesn’t execute those tests, doesn’t learn from the results, and can’t adapt when the form changes.
Agentic AI in software testing does all of that autonomously. It takes a goal, builds a plan, executes steps (including calling tools, reading the DOM, running assertions, and retrying failures), learns from what it observes, and loops back through the cycle, independently.
As UiPath articulates, traditional AI in testing “automates tasks in particular,” whereas agentic AI adds a new layer, agents that make decisions, adapt to changes, and execute workflows dynamically.
The Architecture Behind Agentic AI Testing
This section details the anatomy of an AI testing agent. Every agentic testing system has five interconnected components:
1. Perception Layer
The agent observes the application under test, reads the DOM, captures screenshots, parses API responses, and interprets visual interfaces.
2. Reasoning Engine (LLM Core)
The reasoning engine, typically a fine-tuned or prompted large language model, processes the observed state, historical context, and the defined testing goal to decide what action to take next. This is where agentic AI makes decisions, selects tools, and prioritizes which test path to pursue.
3. Memory System Agents
Memory System Agents that operate without memory are stateless and cannot learn. Modern agentic testing frameworks implement:
Short-term memory: Context retention within a single test session
Long-term memory: Knowledge of past failures, healed locators, and test history
Vector/graph-based storage: For complex retrieval of execution patterns and application behavior
4. Tool Use Layer Agents
Tool Use Layer Agents are given access to tools such as browser automation APIs, database connectors, REST clients, CI/CD hooks, and reporting engines. The reasoning engine decides which tool to call, with what parameters, and evaluates the result.
5. Feedback and Learning Loop
Unlike static scripts, agentic systems incorporate reinforcement signals from coverage metrics, pass/fail rates, and defect correlation. This closed-loop mechanism continuously improves the agent’s testing strategy over time.
Multi-Agent Architecture
The most advanced agentic testing implementations use multi-agent orchestration, specialized agents working in parallel on different testing concerns:
- Test Generation Agent: Reads requirements, user stories, or API specs and produces test cases
- Test Execution Agent: Navigates the application, interacts with UI elements, and runs assertions
- Validation Agent: Reviews test outputs, checks for false positives, and assesses coverage
- Self-Healing Agent: Detects broken locators or changed UI flows and autonomously repairs them
- Orchestrator Agent: Coordinates all other agents, manages priorities, and resolves conflicts
Core Capabilities of Agentic AI in Software Testing
Autonomous Test Case Generation
Agentic AI reads requirements documents, user stories, Jira tickets, API specifications, or OpenAPI schemas and generates comprehensive test cases without human scripting. This includes:
- Positive and negative test cases
- Edge case detection based on data analysis
- Boundary value tests derived from field constraints
- Business logic validation aligned to acceptance criteria
The generation process is iterative; agents refine test cases based on execution outcomes, adding coverage where failures reveal blind spots.
Exploratory Testing at Machine Speed
One of the most underexplored capabilities of agentic testing: autonomous exploratory testing. Traditional exploratory testing requires skilled human testers who intuitively navigate an application looking for unexpected behavior.
Agentic AI agents can simulate this at scale – exploring untested flows, trying unusual input combinations, navigating through unscripted user journeys, and flagging anomalies. This is not random fuzzing. The agent uses context-aware decision-making to prioritize high-risk areas of the application based on code changes, historical defect density, and business criticality.
Self-Healing Test Automation
The maintenance burden of traditional test automation is the primary reason most QA teams achieve less than 25% automation coverage. When UI elements move, class names change, or page flows are restructured, scripts break.
Agentic AI software testing eliminates this through self-healing:
- The agent detects that a previously reliable locator now fails
- It applies visual recognition and semantic analysis to identify the correct element
- It updates the test logic in real time
- It logs the change for auditability
Cut test maintenance by upto 90% with autonomous self-healing capabilities
Risk-Based Test Prioritization
Not all tests deserve equal execution priority. Agentic AI analyzes:
- Recent code commits and affected modules
- Historical defect patterns by feature area
- Business impact scores for failed scenarios
- User behavior analytics indicating high-traffic flows
The agent then dynamically reorders test suite execution to maximize defect discovery within the available time, which is a critical capability for fast-paced CI/CD pipelines where regression runs must complete within minutes.
Natural Language Test Authoring
Agentic testing platforms accept plain-English instructions from non-technical stakeholders:
“Test that a user can complete a purchase with a saved payment method on mobile.”
The agent interprets this intent, decomposes it into steps, executes the test, and reports results, without the business user needing any technical knowledge of automation frameworks.
Predictive Defect Detection
Using probabilistic models such as variational autoencoders (VAEs) and Bayesian networks, AI testing agents forecast the likelihood of failure before tests are run. By analyzing historical data, code change impact, and application state, agents can proactively alert engineering teams to high-risk areas, shifting quality assurance further left in the SDLC.
Synthetic Test Data Generation
Agentic AI can simulate rare but critical scenarios that are hard to replicate manually, such as fraudulent transactions in financial systems, edge-case patient records in healthcare, or multi-step checkout failures in eCommerce, using intelligent synthetic data generation that respects data privacy requirements while ensuring edge case coverage.
Benefits of Agentic AI Testing Over Traditional Automation
Faster Release Cycles Without Sacrificing Quality
Agentic testing compresses the feedback loop. Teams report 70–78% faster test execution after adopting agentic AI platforms. When tests are generated automatically, run in parallel, self-heal, and report results in structured formats, the time from code commit to quality signal shrinks from hours to minutes.
Dramatically Reduced Test Maintenance
Teams using self-healing agentic agents reduce test maintenance overhead by up to 90%. This frees engineers to focus on product development rather than keeping scripts synchronized with an evolving UI.
Higher and Smarter Test Coverage
Conventional automation scripts only validate the scenarios they were written for. Agentic AI explores the application dynamically, discovering edge cases and untested paths that human testers miss under time pressure. Multi-agent systems executing parallel exploration can achieve broader application coverage than any fixed script library.
80% test coverage in 2 weeks. No scripts, no maintenance, no guesswork.
Democratization of Testing
Agentic AI for software testing lowers the technical barrier to entry. Business analysts, product managers, and domain experts can author tests in natural language, broadening quality ownership beyond a specialized QA team.
Resilience to Application Changes
Applications that change frequently, such as SaaS platforms, e-commerce sites, and mobile apps, are poorly served by brittle script-based automation. Agentic testing adapts continuously, making it the natural fit for agile and DevOps environments.
Types of Tests Agentic AI Can Run Autonomously
Most competitor articles cover only functional and regression testing. Here is a more complete taxonomy:
Functional Testing
Agentic AI validates that application features behave as specified. It generates test scenarios from requirements and executes them across UI, API, and database layers simultaneously.
Regression Testing
After each code change, agents execute a risk-prioritized subset of the full regression suite, running the most impactful tests first, expanding coverage based on available time and failure discovery.
Exploratory Testing
Autonomous agents navigate the application without predefined scripts, mimicking the intuitive behavior of experienced human exploratory testers at machine speed and scale.
End-to-End Testing
Agentic systems coordinate testing across multiple application layers and systems, from UI interactions through API calls to database state validation, treating the full user journey as the unit of test.
API Testing
Agents parse OpenAPI/Swagger specifications, generate request payloads, execute API calls, validate responses, and test for security misconfigurations, all autonomously.
Performance and Load Testing
Agentic orchestration manages the simulation of large numbers of concurrent users, monitors response times, and flags performance regressions without manual load profile configuration.
Visual Regression Testing
Computer vision models detect pixel-level and layout changes between application versions, catching visual bugs that logic-based assertions miss.
Accessibility Testing
Agents automatically apply WCAG guidelines, testing keyboard navigation, screen reader compatibility, color contrast ratios, and ARIA attribute correctness.
Security Testing
Agentic AI can conduct basic security validation – testing for injection vulnerabilities, authentication bypass scenarios, and data exposure issues, as part of the standard test cycle.
Cross-Browser and Cross-Device Testing
Agents orchestrate parallel execution across browser types, versions, operating systems, and real device configurations, ensuring consistent behavior across the full user base.
How BotGauge Approaches Agentic AI Testing

Other AI test automation platforms still expect your team to manage tests, maintain scripts, and interpret results. BotGauge’s Autonomous QA as a Solution (AQaaS) model hands that entire responsibility over to AI agents and domain FDE (Forward Deployed Engineer) pods, from test planning and generation to execution, maintenance, and reporting.
You drop in a PRD, a demo video, or a UX flow. BotGauge builds the test suite, keeps it up to date as your app changes, and runs it against every release. No setup cost, no scripted maintenance, no headcount overhead.
A few specifics worth knowing:
- 80% test coverage in 2 weeks, guaranteed
- Critical flows automated in 24 – 48 hours
- Self-healing agent handles DOM and workflow changes automatically
- Fully codeless, cloud-based, SOC 2 Type II compliant
- Outcome-based pricing – you pay for coverage delivered, not licenses
If your team is spending more time managing tests than shipping product, that’s the problem BotGauge is designed to fix.
BotGauge runs a free bug report on your app before you commit to anything
Challenges in Agentic AI Testing and How to Overcome Them
Challenge 1: Non-Determinism and Test Reliability
Agentic AI systems exhibit stochastic behavior – the same test scenario may be handled differently across runs. This makes it difficult to establish stable pass/fail baselines.
Solution: Implement run-level aggregation – assess test outcomes across multiple executions rather than single runs. Establish statistical confidence thresholds. Use structured, sandboxed execution environments to reduce variability due to external state.
Challenge 2: Legacy System Incompatibility
Many enterprise applications, particularly SAP, mainframe systems, and custom desktop apps, don’t expose clean APIs or modern DOM structures that AI agents can interpret.
Solution: Assess integration compatibility during the readiness phase. Use middleware adapters where API access is unavailable. Consider hybrid approaches where agentic AI handles modern application layers and traditional automation covers legacy systems.
Challenge 3: Security and Data Privacy
AI agents interact with multiple databases and systems, often processing sensitive user information. Prompt injection attacks, in which malicious inputs manipulate agent behavior, are an emerging threat specific to LLM-based systems.
Solution: Implement strict input sanitization before agent processing. Use data masking and synthetic data generation for test environments. Conduct regular security audits of agent decision logs. Establish clear data residency policies for any data processed by the AI layer.
Challenge 4: Model Drift
Agentic systems can degrade over time as the relationship between input patterns and expected outputs shifts, a phenomenon called model drift. If not monitored, agents begin making poor testing decisions that produce misleading results.
Solution: Establish performance baselines at deployment. Monitor agent outputs for anomalous patterns. Schedule regular model evaluation reviews. Implement canary testing: compare a monthly subset of agent decisions against human expert review.
Challenge 5: The “Black Box” Problem
AI agents make autonomous decisions that can be difficult for human teams to interpret and audit. This raises concerns about reliability, compliance, and accountability, particularly in regulated industries.
Solution: Require your testing platform to provide full decision logs, tool call traces, and reasoning chains. Implement human-in-the-loop checkpoints for high-stakes test decisions. Treat agent audit trails as first-class compliance artifacts.
Challenge 6: False Positives and Hallucinations
LLM-based agents can produce erroneous test outputs, misclassifying passing behavior as failures or, worse, reporting successful tests on scenarios that weren’t actually validated.
Solution: Layer AI test outputs with rule-based validation checks. Conduct statistical sampling of agent-reported results with human expert review. Implement structured output parsing to catch malformed test assertions before they enter the result pipeline.
Key Takeaways
The software testing landscape has reached an inflection point. The tools that defined the last decade of test automation are no longer adequate for the speed, complexity, and intelligence of modern software development.
Agentic AI in software testing is a fundamental rearchitecting of how quality is assured, from reactive validation to proactive, autonomous, continuously learning quality engineering.
Most “agentic” testing platforms in the market today are retrofits: script-first architectures with an AI layer bolted on top. The result is a fragile foundation dressed in intelligent marketing. True agentic testing requires AI-native architecture, built from the ground up around goal-oriented agents, multi-layer orchestration, and closed-loop learning.
BotGauge delivers exactly this. With autonomous test generation from varied input requirements, self-healing execution that eliminates maintenance burden, intelligent multi-layer coverage across UI, API, and functional layers, and enterprise-grade CI/CD integration, BotGauge gives engineering teams the agentic testing infrastructure they need to ship faster and with confidence at any scale.
Frequently Asked Questions
Does agentic AI testing replace human testers?
How does agentic AI testing handle test data privacy?
Can agentic AI testing work with my existing test assets?
What is the difference between autonomous testing and agentic AI testing?
